This detail tutorial shows how to drop pandas column by index, ways to drop unnamed columns, how to drop multiple columns, uses of pandas drop method and much more. Furthermore, in method 8, it shows various uses of pandas dropna method to drop columns with missing values. This Pandas tutorial will show you, by examples, how to use Pandas read_csv() method to import data from .csv files. Finally, we will also learn how to convert data according to specific datatypes (e.g., using Pandas read_csv dtypes parameter). Pandas drop function allows us to remove either columns or rows from a data frame. We do this by passing a list of column names we want to get rid of.

In the customers data frame like the orders data frame we have an unnamed column that doesn't contain any information. Use the pandas dataframe rename () function to modify specific column names. Use the pandas dataframe set_axis () method to change all your column names. Set the dataframe's columns attribute to your new list of column names. To sum up, in this tutorial we learned 8 different ways to remove columns in python pandas dataframe.

We explored the use of df.drop method, df.dropna method, python's del keyword and learned to use their different parameters efficiently. An unnamed column in pandas comes when you are reading CSV file using it. Sometimes we require to drop columns in the dataset that we not required. It not only saves memory but also helpful in analyzing the data efficiently. One approach is removing the NaN value or some other value.

To explain the code example above; we select the columns without columns containing the string 'unnamed'. Furthermore, we used the case parameter so that the contains method is not case-sensitive. Thus, we will get columns named "Unnamed" and "unnamed". In the first row, using Pandas drop, we are also using the inplace parameter so that it changes our dataframe. The axis parameter, however, is used to drop columns instead of indices (i.e., rows). In the next Pandas read .csv example, we will learn how to handle missing values in a Pandas dataframe.
If we have missing data in our CSV file and it's coded in a way that makes it impossible for Pandas to find them we can use the parameter na_values. In the example below, the amis.csv file has been changed and there are some cells with the string "Not Available". Loc operations work by declaring both the rows and columns we want to select but we are going to use it to just select the columns. In order to select columns using loc we pass either a list of column names or a column name range. Unlike the previous method, loc operations create unique data frames which means that we can use both the original and new data frame.

Let's see how to do the same column selection we did above using the Loc operation. In Python, Pandas drop columns and rows from DataFrame. You can use the "drop" method and this function specifies labels from columns or rows. The Pandas.drop() method deletes columns and rows by directly mentioning the column names or indexes. When you have a list of column names to drop, create a list object with the column names and use it with drop() method or directly use the list.

The Below examples delete columns Courses and Fee from DataFrame. In this example, we have selected the 'val2' column name to remove from Pandas dataframe. To do this task we have to use the df.drop() method and this function will help you to drop specific column names from the dataframe. The drop function can be used to delete columns by number or position by retrieving the column name first for .drop.

To get the column name, provide the column index to the Dataframe.columns object which is a list of all column names. The name is then passed to the drop function as above. It's of course also possible to remove the unnamed columns after we have loaded the CSV to a dataframe. To remove the unnamed columns we can use two different methods; loc and drop, together with other Pandas dataframe methods.

When using the drop method we can use the inplace parameter and get a dataframe without unnamed columns. The article shows how to read and write CSV files using Python's Pandas library. To read a CSV file, the read_csv() method of the Pandas library is used.

You can also pass custom header names while reading CSV files via the names attribute of the read_csv() method. Finally, to write a CSV file using Pandas, you first have to create a Pandas DataFrame object and then call to_csv method on the DataFrame. By default, the read_csv() method uses the first row of the CSV file as the column headers. Sometimes, these headers might have odd names, and you might want to use your own headers.
Use drop function to delete rows or columns of data in files. I'd be interested in any element of removing rows or columns not covered in the above tutorial – please let me know in the comments. The default way to use "drop" to remove columns is to provide the column names to be deleted along with specifying the "axis" parameter to be 1. I have a data file from columns A-G like below but when I am reading it with pd.read_csv('data.csv') it prints an extra unnamed column at the end for no reason.

In the above code, we have created a dataframe and then use the drop() function on the Pandas DataFrame to remove multiple columns. In this example we will apply the method df.drop() on the dataframe to drop multiple columns. We will use an array of column labels and select index column numbers for dropping. In the above code, we have created a list of tuples and then create a Dataframe object. Now we want to drop the last column of the dataframe we can simply apply the df.columns[-1] method in the del keyword. In the examples in this article, you could easily delete rows and columns to make this more well-formatted.

However, there are times where this is not feasible or advisable. The good news is that pandas and openpyxl give us all the tools we need to read Excel data - no matter how crazy the spreadsheet gets. DataFrame has a method called drop() that removes rows or columns according to specify column names and corresponding axis. To delete or remove only one column from Pandas DataFrame, you can use either del keyword, pop () function or drop () function on the dataframe.

To delete multiple columns from Pandas Dataframe, use drop () function on the dataframe. In this example, we will create a DataFrame and then delete a specified column using del keyword. Removing columns and rows from your DataFrame is not always as intuitive as it could be. The drop function allows the removal of rows and columns from your DataFrame, and once you've used it a few times, you'll have no issues. In this post, I have covered the basics of how to drop columns in Pandas dataframe. In the next post, I will cover how to drop rows of Pandas DataFrame.

In this tutorial, we will cover how to drop or remove one or multiple columns from pandas dataframe. Often we will only want to use only certain columns from our data frames. The simplest way to select a subset of columns is to simply pass a list of the column names you want to select in between brackets. In this drop column article, you have learned how to remove or delete a column, two or more columns from DataFrame by name, labels, index. Also, you have learned how to remove columns between two columns and many more examples.
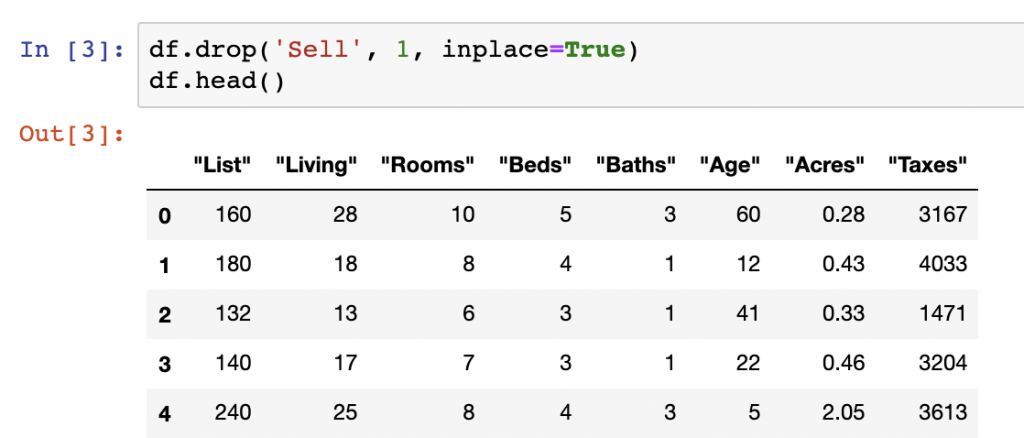
In one of the above examples, I have explained how to remove/delete columns from the list of columns. Now let's see another example doing the same iteratively. Use the below example to delete columns 0 and 1 index.

In the above code, we have removed two specific columns that are 'Stu_name' and 'Stu_id'. Once you will print 'new_val' then the output will display the updated dataframe. You can use the drop function to delete rows and columns in a Pandas DataFrame. Pandas is a very powerful and popular framework for data analysis and manipulation. One of the most striking features of Pandas is its ability to read and write various types of files including CSV and Excel. You can effectively and easily manipulate CSV files in Pandas using functions like read_csv() and to_csv().

The second most common requirement for deleting rows from a DataFrame is to delete rows in groups, defined by values on various columns. The best way to achieve this is through actually "selecting" the data that you would like to keep. The DataFrame index is displayed on the left-hand side of the DataFrame when previewed.

To delete rows from a DataFrame, the drop function references the rows based on their "index values". Most typically, this is an integer value per row, that increments from zero when you first load data into Pandas. You can see the index when you run "data.head()" on the left hand side of the tabular view. You can access the index object directly using "data.index" and the values through "data.index.values". At the start of every analysis, data needs to be cleaned, organised, and made tidy.

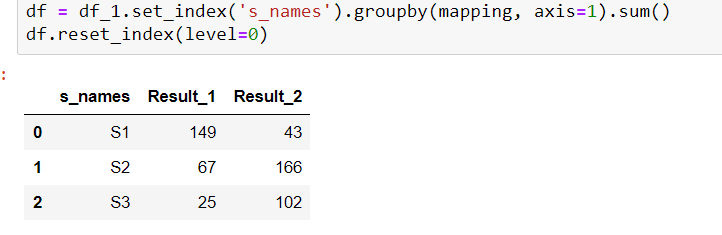
The Pandas Drop function is key for removing rows and columns. This is done to create two new columns, named Group and Row Num. The important part is Group which will identify the different dataframes. In the last row of the code example we use Pandas to_csv to write the dataframes to CSV. Browse other questions tagged python pandas dataframe or ask your own question.

Axis – Use 1 to drop columns and 0 to drop rows from DataFrame. By using the df.drop() method we can perform this particular task and in this example first, we have created a dictionary and contains key-value pair elements. Now use the df.drop() method and assign a specific column value.

We selected a portion of dataframe, that included all rows, but it selected only n-1 columns i.e. from first column onwards. So, basically it removed the first column of dataframe. In this article, we will discuss different ways to delete first column of a pandas dataframe in python. When writing a DataFrame to a CSV file, you can also change the column names, using the columns argument, or specify a delimiter via the sep argument. If you don't specify either of these, you'll end up with a standard Comma-Separated Value file. The simplest solution for this data set is to use the headerand usecolsarguments to read_excel().

The usecolsparameter, in particular, can be very useful for controlling the columns you would like to include. With pandas it is easy to read Excel files and convert the data into a DataFrame. Unfortunately Excel files in the real world are often poorly constructed. In those cases where the data is scattered across the worksheet, you may need to customize the way you read the data.

This article will discuss how to use pandas and openpyxl to read these types of Excel files and cleanly convert the data to a DataFrame suitable for further analysis. One way of renaming the columns in a Pandas dataframe is by using the rename() function. This method is quite useful when we need to rename some selected columns because we need to specify information only for the columns which are to be renamed.

Now we are ready to learn how to save Pandas dataframe to CSV. It's quite simple, we write the dataframe to CSV file using Pandas to_csv method. In the example below we don't use any parameters but the path_or_buf which is, in our case, the file name. Note, to get the above output we used Pandas iloc to select the first 7 rows. This was done to get an output that could be easier illustrated. That said, we are now continuing to the next section where we are going to read certain columns to a dataframe from a CSV file.

Remove rows or columns by specifying label names and corresponding axis, or by specifying directly index or column names. You can specify all the columns you want to remove in a list and pass it in drop function. Pandas uses PyTables for reading and writing HDF5 files, which allows serializing object-dtype data with pickle. Loading pickled data received from untrusted sources can be unsafe. This is useful for numerical text data that has leading zeros. By default columns that are numerical are cast to numeric types and the leading zeros are lost.

To avoid this, we can convert these columns to strings. Pandas is able to read and write line-delimited json files that are common in data processing pipelines using Hadoop or Spark. First, create a pandas DataFrame with a dictionary of lists. On our DataFrame, we have column names Courses, Fee and Duration. Now, let's see the drop() syntax and how to delete or drop columns from DataFrame with examples. To drop the last column of the dataframe first, we set the position at -1 and then select the column bypassing the column name in the del method.
By using the del keyword we can easily drop the last column of Pandas DataFrame. In Python, the del keyword is used to remove the variable from namespace and delete an object like lists and it does not return any type of value. To delete that column we have used it's index value in pandas drop method. Using the drop method we can provide the index number for the column. Dropna() is specially written to find and delete the rows or columns with the missing value. Using drop method we can provide the index number for the column.

You can obviously remove not only columns but also rows. In this case we'll pass the list of indices to remove using a list into the index parameter. Create a simple dataframe with dictionary of lists, say column names are A, B, C, D, E.

Use drop() to remove first column of pandas dataframe. Hmm, now we've got our custom headers, but the first row of the CSV file, which was originally used to set the column names is also included in the DataFrame. We'll want to skip this line, since it no longer holds any value for us.